
As AI becomes increasingly integrated into our daily lives, building models with privacy at their core is a critical frontier. Differential privacy (DP) offers a mathematically sound solution by adding calibrated noise to prevent data memorization. However, applying DP to large language models (LLMs) introduces trade-offs, such as altered scaling laws, reduced training stability, and significantly increased batch sizes and computation costs.

Through new research conducted in partnership with Google DeepMind, we have established scaling laws that accurately model these intricacies, providing a complete picture of compute-privacy-utility trade-offs. Guided by this research, we introduce VaultGemma, the largest (1B-parameter) open model trained from scratch with differential privacy. We are releasing the weights on Hugging Face and Kaggle, alongside a technical report, to advance the development of the next generation of private AI.
Understanding the Scaling Laws
With a carefully thought-out experimental methodology, we aimed to quantify the benefits of increasing model sizes, batch sizes, and iterations in DP training. Our work required simplifying assumptions to overcome the exponential number of possible combinations. We found that model learning depends primarily on the “noise-batch ratio,” which compares the amount of random noise added for privacy to the size of training batches. This assumption holds because the privacy noise we add is much greater than any natural randomness from data sampling.

To establish DP scaling laws, we conducted comprehensive experiments evaluating performance across various model sizes and noise-batch ratios. The resulting empirical data, combined with known deterministic relationships between variables, allows us to answer important questions like: “For a given compute budget, privacy budget, and data budget, what is the optimal training configuration to achieve the lowest possible training loss?”
Key Findings: A Powerful Synergy
Before diving into full scaling laws, it’s useful to understand the dynamics between compute budget, privacy budget, and data budget from a privacy accounting perspective. This analysis, which doesn’t require model training, yields valuable insights. For instance, increasing the privacy budget alone leads to diminishing returns unless coupled with corresponding increases in either compute budget (FLOPs) or data budget (tokens).
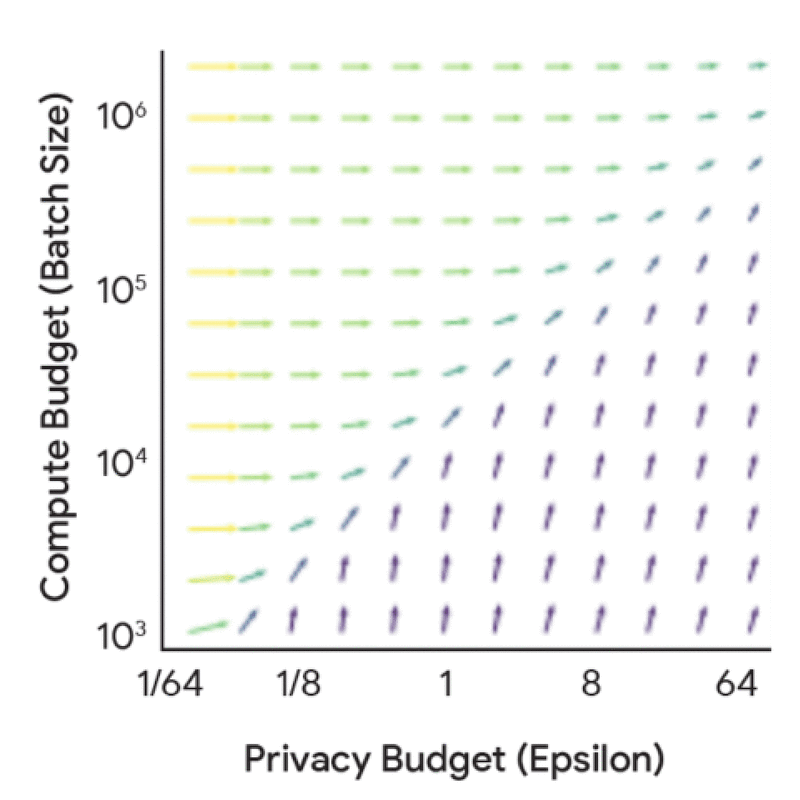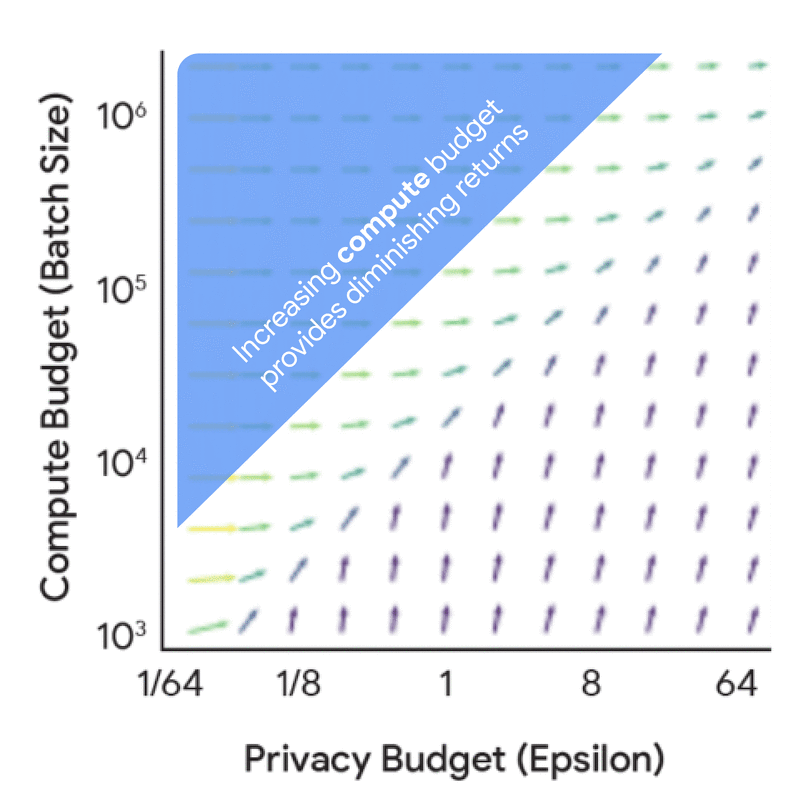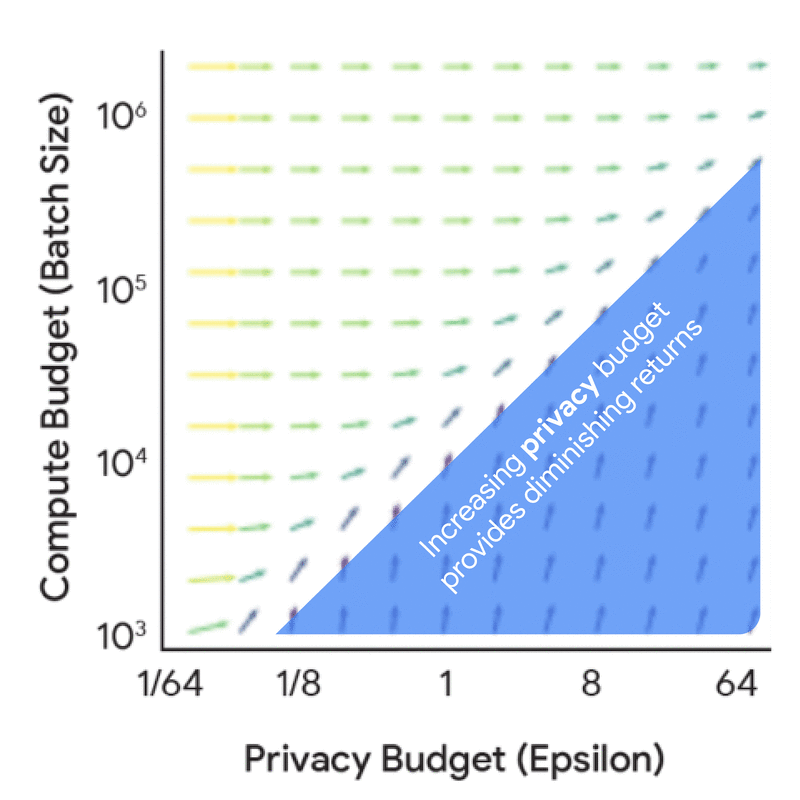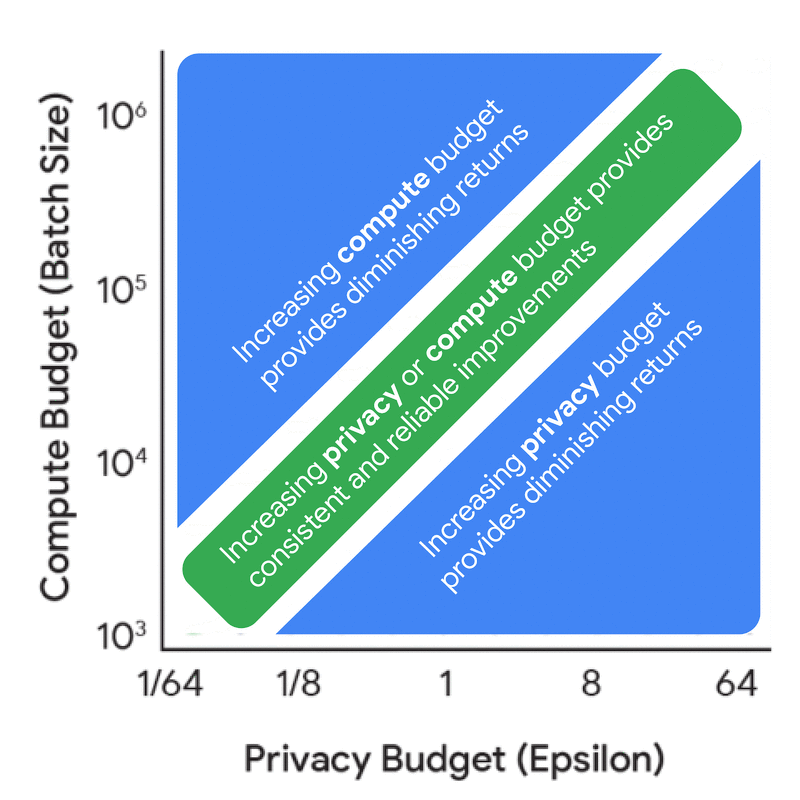
Further exploration reveals how optimal training configurations change based on different constraints. As privacy and compute budgets vary, recommendations shift between investing in larger models versus training with larger batch sizes or more iterations.
This data provides practitioners with valuable insights. A key finding is that one should train much smaller models with much larger batch sizes than would be used without DP. While this general insight holds across many settings, optimal training configurations do change with privacy and data budgets. Understanding these exact trade-offs is crucial for judicious use of both compute and privacy budgets in real training scenarios.
Applying the Scaling Laws to Build VaultGemma
The Gemma models, designed with responsibility and safety at their core, provided a natural foundation for developing VaultGemma. Our scaling laws represented an important first step toward training a useful Gemma model with DP, helping determine both the compute needed for a compute-optimal 1B parameter Gemma 2-based model and how to allocate that compute among batch size, iterations, and sequence length.
One prominent gap between scaling law research and actual VaultGemma training was our handling of Poisson sampling, a central component of DP-SGD. We initially used uniform batch loading but switched to Poisson sampling for better privacy guarantees with less noise. This method created batches of different sizes and required specific randomized data processing order. We solved this using our recent work on Scalable DP-SGD, which allows processing data in fixed-size batches while maintaining strong privacy protections.
Results
Armed with new scaling laws and advanced training algorithms, we built VaultGemma—the largest open model fully pre-trained with differential privacy using an approach that yields high-utility models. From training VaultGemma, we found our scaling laws to be highly accurate, with final training loss remarkably close to our predictions, validating our research and providing the community with a reliable roadmap for future private model development.

We compared downstream performance against non-private counterparts across standard academic benchmarks (HellaSwag, BoolQ, PIQA, SocialIQA, TriviaQA, ARC-C, ARC-E). To contextualize this performance and quantify current resource investments required for privacy, we included comparisons to older similar-sized GPT-2 models. This comparison shows that today’s private training methods produce models with utility comparable to non-private models from roughly five years ago, highlighting the important gap our work will help systematically close.
Privacy Protections
VaultGemma comes with strong theoretical and empirical privacy protections. The model was trained with a sequence-level DP guarantee of (ε ≤ 2.0, δ ≤ 1.1e-10), where a sequence consists of 1024 consecutive tokens from heterogeneous data sources. We used the same training mixture as Gemma 2, with long documents split into multiple sequences and shorter documents packed together.
In practice, this means that if information relating to any potentially private fact occurs in a single sequence, VaultGemma essentially doesn’t know that fact: responses to queries will be statistically similar to results from a model that never trained on that sequence. However, if many training sequences contain information relevant to a particular fact, VaultGemma can provide that information.
To complement our sequence-level DP guarantee, we conducted additional empirical privacy tests. When prompted with 50-token prefixes from training documents, VaultGemma 1B showed no detectable memorization of training data, successfully demonstrating DP training efficacy.
VaultGemma represents a significant step forward in building AI that is both powerful and private by design. While a utility gap still exists between DP-trained and non-DP-trained models, we believe this gap can be systematically narrowed with more research on mechanism design for DP training. We hope VaultGemma and our accompanying research will empower the community to build the next generation of safe, responsible, and private AI for everyone.