
Built as a thinking agent, it reasons step by step while using tools, achieving state-of-the-art performance on Humanity’s Last Exam (HLE), BrowseComp, and other benchmarks, with major gains in reasoning, agentic search, coding, writing, and general capabilities.
Kimi K2 Thinking can execute up to 200 – 300 sequential tool calls without human interference, reasoning coherently across hundreds of steps to solve complex problems.
It marks our latest efforts in test-time scaling, by scaling both thinking tokens and tool calling steps.
K2 Thinking is now live on kimi.com under the chat mode [1], with its full agentic mode available soon. It is also accessible through the Kimi K2 Thinking API.
Evaluations
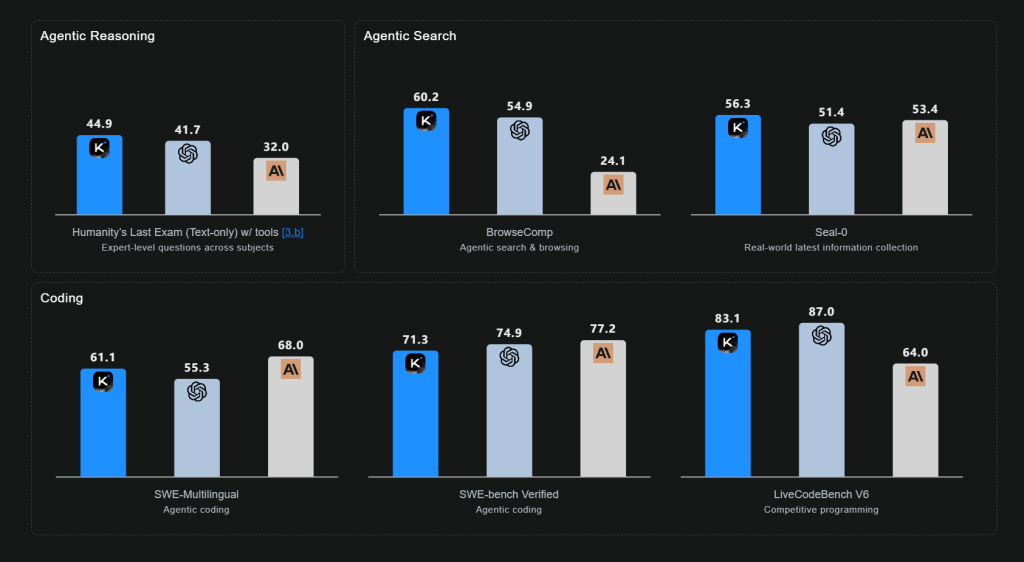
Kimi K2 Thinking sets new records across benchmarks that assess reasoning, coding, and agent capabilities. K2 Thinking achieves 44.9% on HLE with tools, 60.2% on BrowseComp, and 71.3% on SWE-Bench Verified, demonstrating strong generalization as a state-of-the-art thinking agent model.
Agentic Reasoning
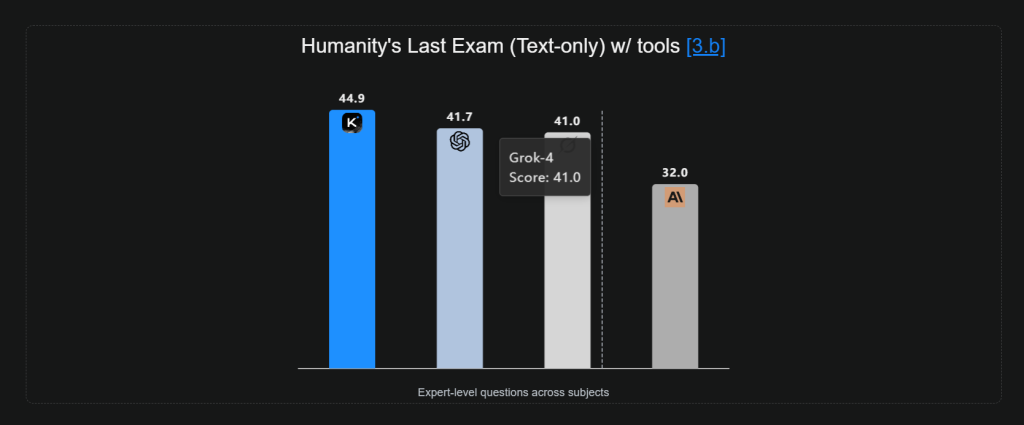
K2 Thinking demonstrates outstanding reasoning and problem-solving abilities. On Humanity’s Last Exam (HLE)—a rigorously crafted, closed‑ended benchmark—spanning thousands of expert‑level questions across more than 100 subjects, K2 Thinking achieved a state-of-the-art score of44.9%, with search, python, and web-browsing tools, establishing new records in multi‑domain expert‑level reasoning performance.
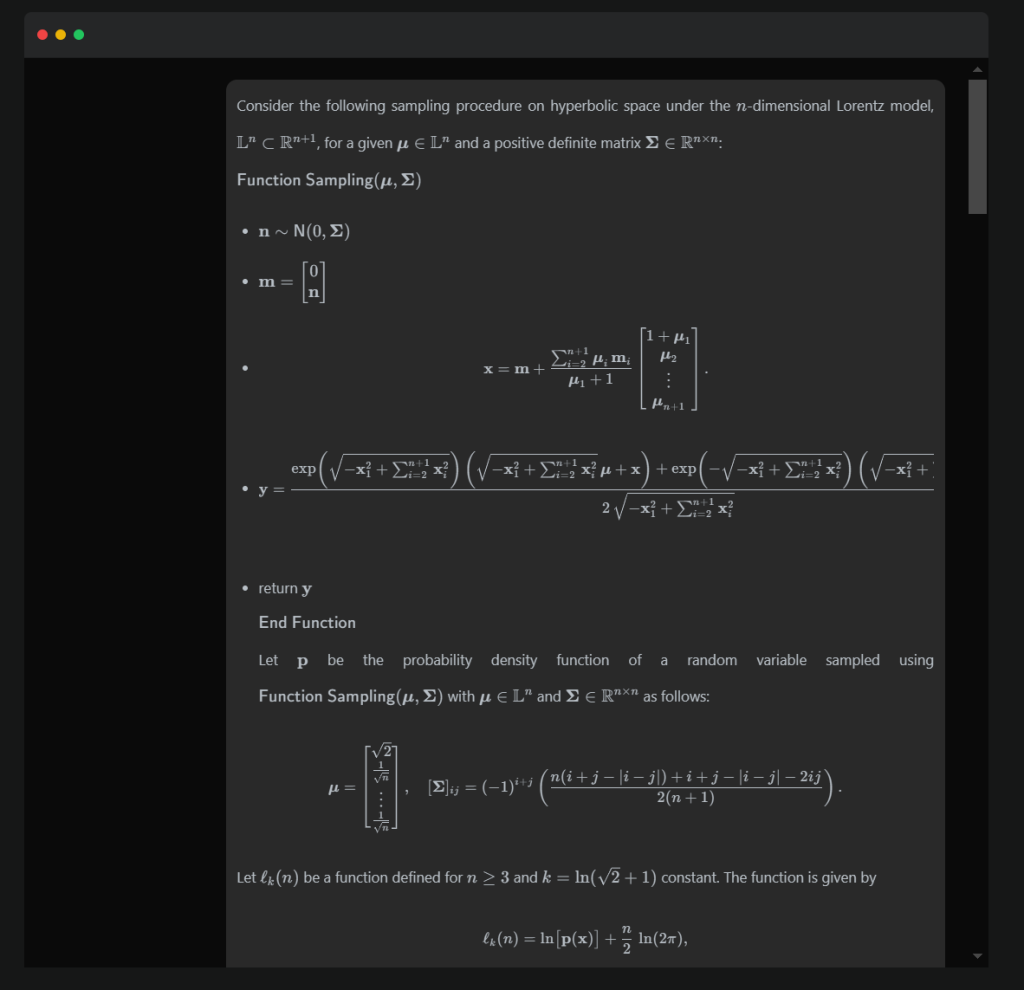
By reasoning while actively using a diverse set of tools, K2 Thinking is capable of planning, reasoning, executing, and adapting across hundreds of steps to tackle some of the most challenging academic and analytical problems. In one instance, it successfully solved a PhD-level mathematics problem through 23 interleaved reasoning and tool calls, exemplifying its capacity for deep, structured reasoning and long-horizon problem solving:
Agentic Coding
K2 Thinking exhibits substantial gains in coding and software development tasks. It achieves scores of 61.1% on SWE-Multilingual, 71.3% on SWE-Bench Verified, and 47.1% on Terminal-Bench, showcasing strong generalization across programming languages and agent scaffolds.
The model delivers notable improvements on HTML, React, and component-intensive front-end tasks—translating ideas into fully functional, responsive products. In agentic coding settings, it reasons while invoking tools, integrating fluidly into software agents to execute complex, multi-step development workflows with precision and adaptability.
Agentic Search and Browsing
K2 Thinking demonstrates strong performance in agentic search and browsing scenarios. On BrowseComp—a challenging benchmark designed to evaluate models’ ability to continuously browse, search, and reason over hard-to-find real-world web information—K2 Thinking achieved a score of 60.2%, significantly outperforming the human baseline of 29.2%. This result highlights K2 Thinking’s superior capability for goal-directed, web-based reasoning and its robustness in dynamic, information-rich environments.
K2 Thinking can execute 200–300 sequential tool calls, driven by long-horizon planning and adaptive reasoning. It performs dynamic cycles of think → search → browser use → think → code, continually generating and refining hypotheses, verifying evidence, reasoning, and constructing coherent answers. This interleaved reasoning allows it to decompose ambiguous, open-ended problems into clear, actionable subtasks.


General Capabilities
Creative Writing: K2 Thinking delivers improvements in completeness and richness. It shows stronger command of style and instruction, handling diverse tones and formats with natural fluency. Its writing becomes more vivid and imaginative—poetic imagery carries deeper associations, while stories and scripts feel more human, emotional, and purposeful. The ideas it expresses often reach greater thematic depth and resonance.
Practical Writing: K2 Thinking demonstrates marked gains in reasoning depth, perspective breadth, and instruction adherence. It follows prompts with higher precision, addressing each requirement clearly and systematically—often expanding on every mentioned point to ensure thorough coverage. In academic, research, and long-form analytical writing, it excels at producing rigorous, logically coherent, and substantively rich content, making it particularly effective in scholarly and professional contexts.
Personal & Emotional: When addressing personal or emotional questions, K2 Thinking responds with more empathy and balance. Its reflections are thoughtful and specific, offering nuanced perspectives and actionable next steps. It helps users navigate complex decisions with clarity and care—grounded, practical, and genuinely human in tone.
Inference Efficiency
Low-bit quantization is an effective way to reduce inference latency and GPU memory usage on large-scale inference servers. However, thinking models use excessive decoding lengths, and thus quantization often results in substantial performance drops.
To overcome this challenge, we adopt Quantization-Aware Training (QAT) during the post-training phase, applying INT4 weight-only quantization to the MoE components. It allows K2 Thinking to support native INT4 inference with a roughly 2x generation speed improvement while achieving state-of-the-art performance. All benchmark results are reported under INT4 precision.
Full Evaluations
The table below shows that Kimi K2 Thinking matches or surpasses the latest open-source and frontier models across a wide range of tasks, excelling on benchmarks for reasoning, agentic search, and coding.

Footnotes
- To ensure a fast, lightweight experience, we selectively employ a subset of tools and reduce the number of tool call turns under the chat mode on kimi.com. As a result, chatting on kimi.com may not reproduce our benchmark scores. Our agentic mode will be updated soon to reflect the full capabilities of K2 Thinking.
- Testing Details: a. All benchmarks were evaluated at temperature = 1.0 and 256 k context length for K2 Thinking, except for SciCode, for which we followed the official temperature setting of 0.0. b. HLE (no tools), AIME25, HMMT25, and GPQA were capped at a 96k thinking-token budget, while IMO-Answer Bench, LiveCodeBench and OJ-Bench were capped at a 128k thinking-token budget. Longform Writing was capped at a 32k completion-token budget. c. For AIME and HMMT (no tools), we report the average of 32 runs (avg@32). For AIME and HMMT (with Python), we report the average of 16 runs (avg@16). For IMO-AnswerBench, we report the average of 8 runs (avg@8).
- Baselines: a. GPT-5, Claude-4.5-sonnet, Grok-4 results and DeepSeek-V3.2 results are quoted from the GPT-5 post, GPT-5 for Developers post, GPT-5 system card, claude-sonnet-4-5, grok-4, deepseek-v3.2, the public Terminal-Bench leaderboard (Terminus-2), the public Vals AI leaderboard and the artificialanalysis. Benchmarks for which no available public scores were re-tested under the same conditions used for k2 thinking and are marked with an asterisk(*). For the GPT-5 test, we set the reasoning effort to high. b. The GPT-5 and Grok-4 on the HLE full set with tools are 35.2 and 38.6 from their official posts. In our internal evaluation on the HLE text-only subset, GPT-5 scores 41.7 and Grok-4 scores 38.6 (Grok-4’s launch cited 41.0 on the text-only subset). For GPT-5’s HLE text-only w/o tool, we use score from Scale.ai, and the official GPT-5 score on the HLE full set (no tools) is 24.8. c. For IMO-AnswerBench: GPT-5 scored 65.6 in the benchmark paper. We re-evaluated GPT-5 with official API and obtained a score of 76.
- For HLE (w/ tools) and the agentic-search benchmarks: a. K2 Thinking was equipped with search, code-interpreter, and web-browsing tools. b. BrowseComp-ZH, Seal-0, FinSearchComp-T3 were run 4 times independently and the average is reported (avg@4). c. The evaluation used o3-mini as judge, configured identically to the official HLE setting; judge prompts were taken verbatim from the official repository. d. On HLE, the maximum step limit was 120, with a 48 k-token reasoning budget per step; on agentic-search tasks, the limit was 300 steps with a 24 k-token reasoning budget per step. e. When tool execution results cause the accumulated input to exceed the model’s context limit (256k), we employ a simple context management strategy that hides all previous tool outputs. f. The web access to Hugging Face may lead to data leakage in certain benchmark tests, such as HLE. K2 Thinking can achieve a score of 51.3 on HLE without blocking Hugging Face. To ensure a fair and rigorous comparison, we blocked access to Hugging Face during testing.
- For Coding Tasks: a. Terminal-Bench scores were obtained with the default agent framework (Terminus-2) and the provided JSON parser. b. For other coding tasks, the result was produced with our in-house evaluation harness. The harness is derived from SWE-agent, but we clamp the context windows of the Bash and Edit tools and rewrite the system prompt to match the task semantics. c. All reported scores of coding tasks are averaged over 5 independent runs.
- Heavy Mode: K2 Thinking Heavy Mode employs an efficient parallel strategy: it first rolls out eight trajectories simultaneously, then reflectively aggregates all outputs to generate the final result. Heavy mode for GPT-5 denotes the official GPT-5 Pro score.