
The Gemma family of open models continues to expand with exciting innovations. Following the successful releases of Gemma 3, Gemma 3 QAT, and the mobile-first Gemma 3n architecture, the ecosystem has reached a significant milestone with over 200 million downloads. Today marks another leap forward with the introduction of Gemma 3 270M—a compact, hyper-efficient model specifically designed for task-specific fine-tuning.

This new 270-million parameter model brings sophisticated instruction-following capabilities to a remarkably small footprint. Benchmark results demonstrate exceptional performance for its size category, making advanced AI capabilities accessible for both on-device applications and research environments.
Core Capabilities That Set Gemma 3 270M Apart
Compact Architecture with Impressive Capacity: Despite its small size, Gemma 3 270M features 170 million embedding parameters supported by a large 256k token vocabulary, plus 100 million transformer block parameters. This substantial vocabulary enables handling of specific and rare tokens, creating an excellent foundation for domain-specific fine-tuning.
Extreme Energy Efficiency: Internal testing reveals remarkable power optimization—the INT4-quantized model consumed only 0.75% of battery for 25 conversations on a Pixel 9 Pro SoC, establishing it as the most power-efficient model in the Gemma family.
Built-in Instruction Following: The model ships with both pre-trained and instruction-tuned checkpoints, providing strong out-of-the-box performance for general instruction tasks without requiring complex conversational capabilities.
Production-Ready Quantization: Quantization-Aware Trained (QAT) checkpoints ensure minimal performance degradation when running at INT4 precision, making deployment on resource-constrained devices both practical and efficient.
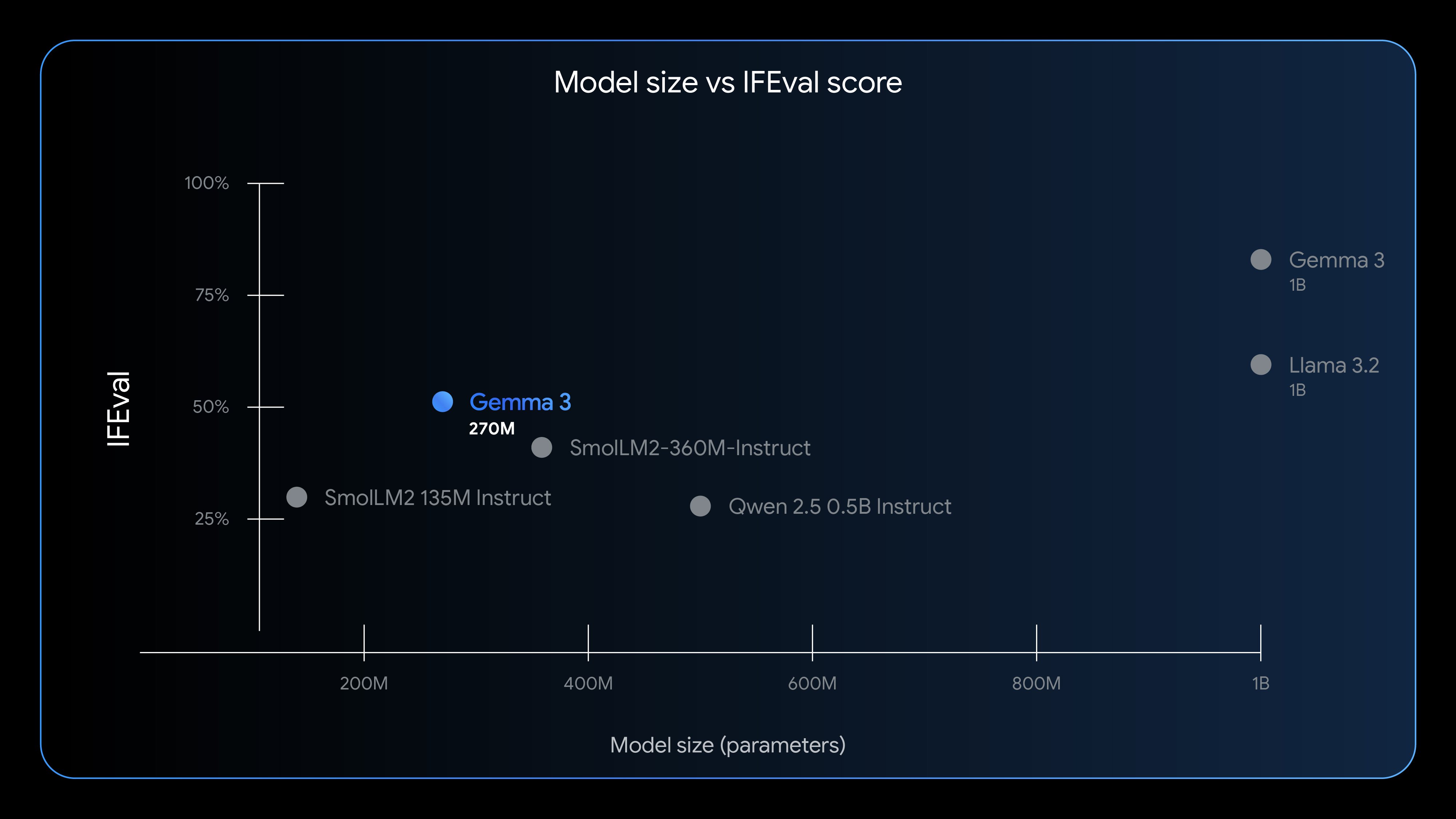
The Right Tool for Specialized Tasks
Gemma 3 270M embodies the engineering principle of using the right tool for the job. Rather than employing oversized general-purpose models, developers can now leverage this compact foundation model that excels when fine-tuned for specific tasks. The true power emerges through specialization—enabling text classification, data extraction, and other focused applications with remarkable accuracy, speed, and cost-effectiveness.
Real-world validation comes from Adaptive ML’s work with SK Telecom, where fine-tuning a Gemma 3 4B model for multilingual content moderation outperformed much larger proprietary models. Gemma 3 270M extends this approach further, allowing developers to create entire fleets of specialized models, each optimized for specific functions.
The specialization advantage extends beyond enterprise applications to creative uses. A compelling example is the Bedtime Story Generator web app powered by Gemma 3 270M through Transformers.js, demonstrating how the model’s size and performance enable offline, web-based creative applications.
When to Choose Gemma 3 270M
This model shines in specific scenarios:
– High-volume, well-defined tasks like sentiment analysis, entity extraction, and compliance checks
– Applications where every millisecond and micro-cent counts, enabling dramatic cost reduction
– Projects requiring rapid iteration and deployment—fine-tuning experiments complete in hours rather than days
– Privacy-sensitive applications that benefit from full on-device operation
– Building multiple specialized task models without budget constraints
Getting Started with Fine-Tuning
The path to customization is straightforward with Gemma 3 270M. Developers can download the model from Hugging Face, Ollama, Kaggle, LM Studio, or Docker. Testing options include Vertex AI and popular inference tools like llama.cpp, Gemma.cpp, LiteRT, Keras, and MLX. Fine-tuning supports favorite frameworks including Hugging Face, UnSloth, and JAX, with deployment flexibility ranging from local environments to Google Cloud Run.
The Gemmaverse continues to prove that innovation comes in all sizes. With Gemma 3 270M, developers gain a powerful tool for building smarter, faster, and more efficient AI solutions tailored to specific needs.