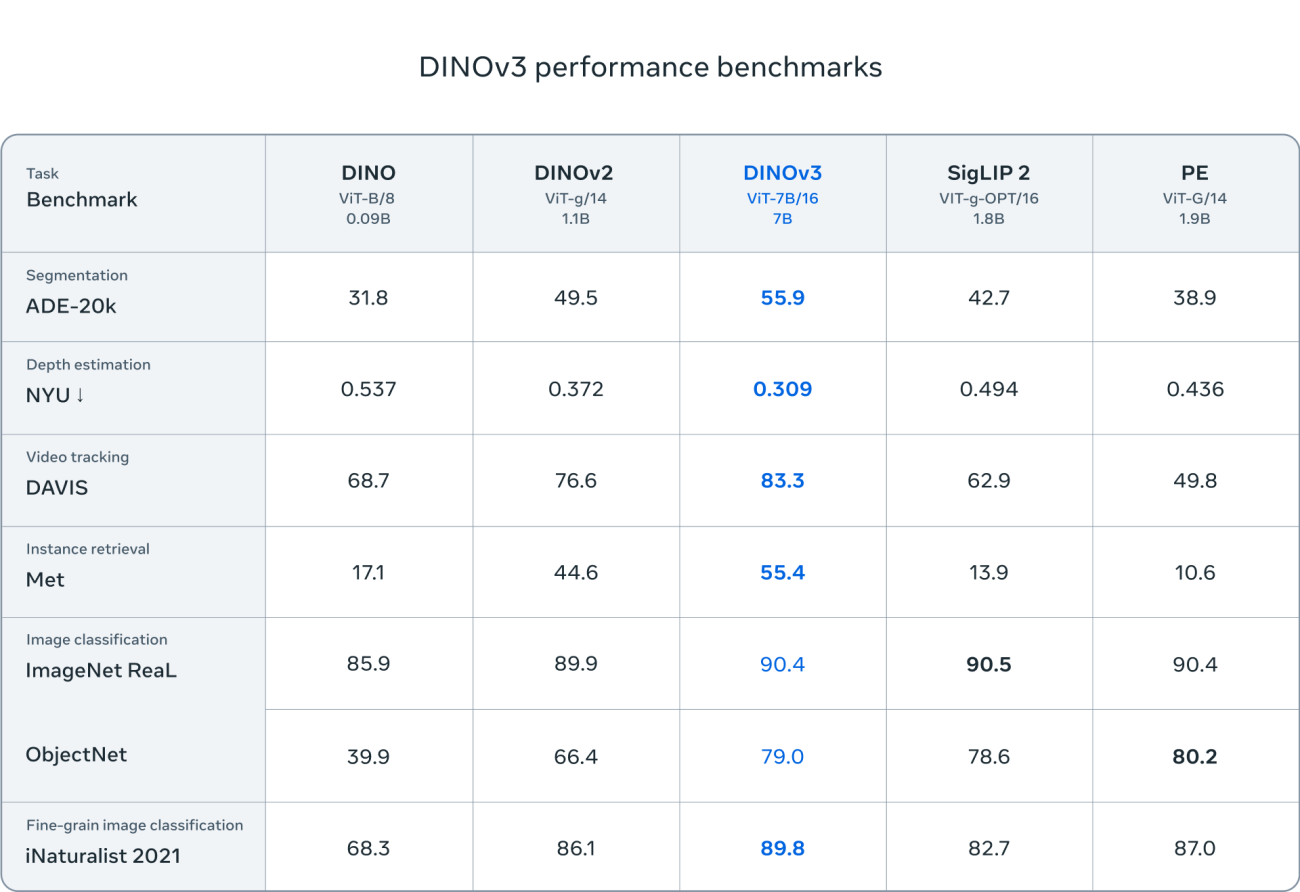
In the rapidly evolving field of computer vision, self-supervised learning has emerged as a transformative approach, enabling models to learn meaningful representations from vast amounts of unlabeled data. DINOv3 represents a significant leap forward in this domain, pushing the boundaries of what’s possible with unprecedented scale and efficiency. By leveraging advanced techniques, it allows for more robust and generalized visual understanding without the need for extensive manual annotations.
The core innovation of DINOv3 lies in its ability to handle massive datasets autonomously, reducing dependency on costly labeled data. This not only accelerates research and development but also opens up new possibilities for applications in areas like autonomous driving, medical imaging, and augmented reality. Its open-source nature ensures that the broader community can build upon these advancements, fostering collaboration and rapid iteration.
As we look to the future, DINOv3 sets a new benchmark for self-supervised learning in vision tasks. Its scalability and performance improvements highlight the potential for AI systems to achieve human-like perception, paving the way for more intelligent and adaptive technologies. Embracing such tools can empower developers and researchers to tackle complex challenges with greater ease and precision.