Quick summary
DeepSeek-OCR (released Oct 2025 by DeepSeek AI) introduces a new idea called “Contexts Optical Compression”: instead of representing very long text solely as language tokens, it maps long textual contexts into visual/optical representations (images) and uses a vision-centric encoder + a decoder to compress and later recover text. The project is open-source (code + weights available) and claims large token-reduction factors (single-digit to ~20×) with reasonable decoding quality, enabling much larger effective context windows for LLM-style systems. (arxiv.org)
What exactly is the technical idea?
- Optical 2D mapping (visual compression). The core is to transform long sequences of text (and document layouts) into high-resolution images that a specialized vision encoder compresses into a much smaller set of “vision tokens.” These vision tokens are then consumed by a (vision-aware) decoder or VLM to reconstruct or reason over the original content. This inverts the usual flow (text → tokens → model) by inserting an image representation as the intermediate compressed form. (arxiv.org)
- Two main components. The published system references a DeepEncoder (for producing low-activation, highly compressed visual representations from high-resolution inputs) and a DeepSeek3B-MoE-A570M (a mixture-of-experts style decoder) that performs interpretation/decoding and downstream reasoning. The design emphasizes keeping the number of vision tokens manageable even for very large inputs. (arxiv.org)
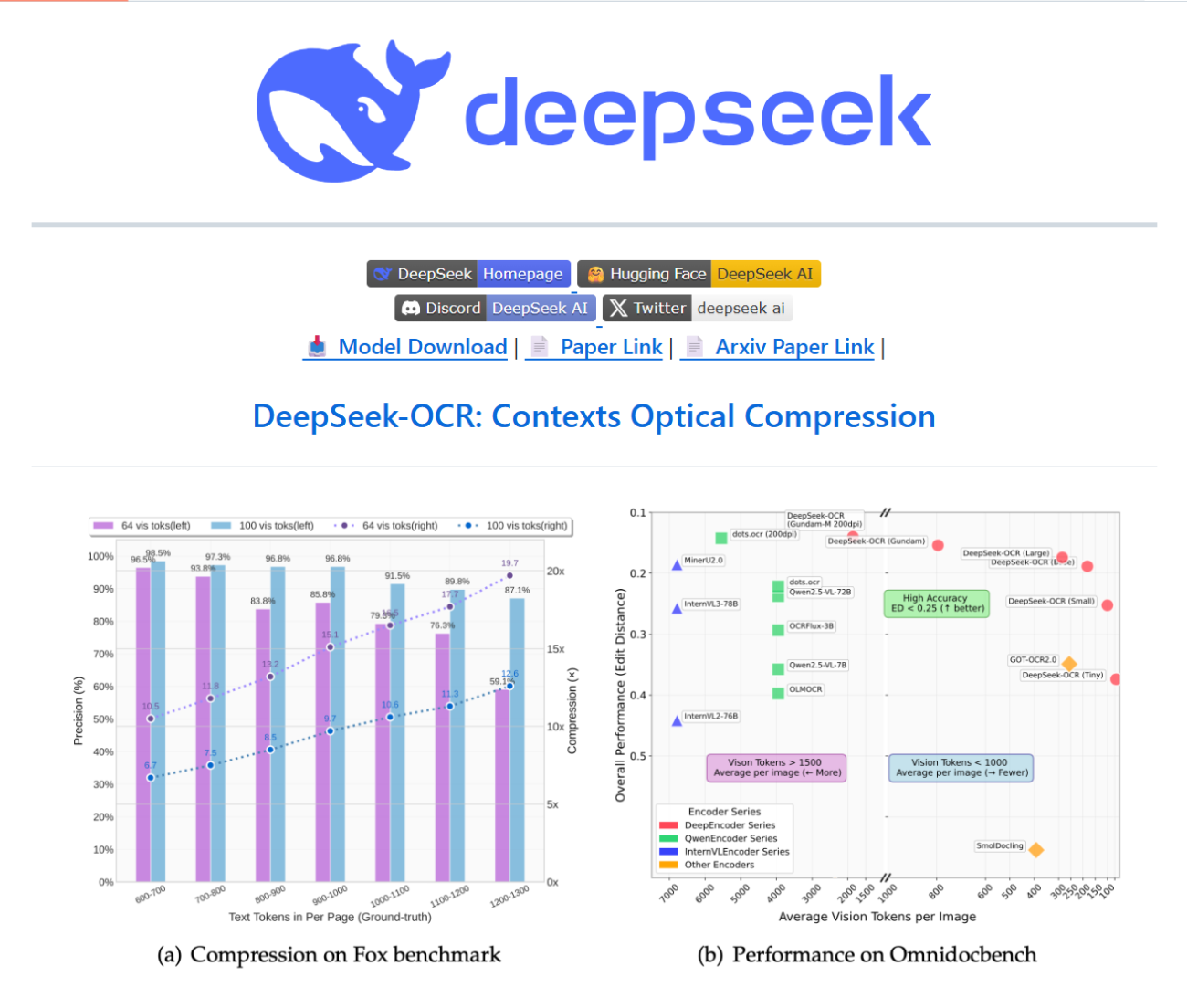
- Empirical claims. Reported compression factors vary by configuration; media and the paper cite 7–20× fewer tokens in visual form versus plain text tokenization, with decoding accuracy that is high at modest compression (paper and press mention ~97% at lower compression levels) and degrades at extreme compression. The system is released on GitHub and Hugging Face for reproducibility and experimentation. (Venturebeat)
Why this is technically significant (breakthroughs)
- Changes the representation paradigm. Rather than treating text as the canonical, singular representation for language models, DeepSeek-OCR shows that visual encodings can be a more compact, efficient intermediary for very long text and complex document layouts (tables, figures, multi-column pages). This is a conceptual shift: “text as images” for compression and retrieval. (InfoQ)
- Large context scaling without linear token blowup. If vision tokens can represent much larger spans of textual content per token, models can effectively access far larger contexts (tens of millions of text-equivalent tokens in principle) without the usual linear compute/memory blowup of tokenized text. That has direct implications for tasks that require entire books, corpora, or huge document collections. (Tom’s Hardware)
- Better native handling of layout/visual information. Documents with rich 2D structure (tables, equations, figures) are inherently spatial. Encoding them optically preserves layout cues that pure linear tokenization loses, improving downstream understanding or table extraction. (iWeaver)
- Practical, open reproducibility. The project released code and weights (GitHub, Hugging Face), lowering the barrier for the community to test, reproduce, and iterate—accelerating research and practical adoption. (GitHub)
Concrete advantages and use cases
- Reduced inference cost for long documents. Fewer tokens → smaller attention matrices → lower memory and FLOPs for the LLM stage, which directly reduces operational cost for long-context tasks (document QA, legal discovery, literature reviews). (Tom’s Hardware)
- High-throughput batch OCR / dataset generation. Reported throughput claims (e.g., hundreds of thousands of pages/day on one A100 in press coverage) make it attractive for building large text corpora from scanned docs. (The Times of India)
- Improved table/diagram extraction and multi-modal retrieval. Scientific papers, invoices, and financial reports can be compressed while preserving spatial semantics, improving retrieval and structured extraction. (iWeaver)
- New architectures for retrieval / memory. Visual compression could be used as a compact long-term memory representation or index in retrieval-augmented systems (store images of passages rather than raw text tokens). (skywork.ai)
Limitations, trade-offs and caveats (be objective)
- Lossy compression at high ratios. The more aggressive the compression, the greater the decoding error rate; accuracy numbers depend heavily on the compression setting and data type. This makes the technique less suitable for cases demanding perfect fidelity (e.g., legal evidence, exact code recovery) unless tuned for near-lossless modes. (Tom’s Hardware)
- Decoder/encoder complexity and compute shift. Compression reduces token count for the LLM, but it introduces cost for the visual encoder/decoder pipeline (and possibly higher I/O for high-res images). The overall system cost depends on where you save/shift compute; it’s not purely “free” compute reduction. (arxiv.org)
- New attack surfaces and robustness concerns. Converting text to images creates vulnerabilities to visual adversarial noise, font/layout variances, or OCR-style failure modes. Reliability across languages, scripts, and low-quality scans must be validated broadly. (IntuitionLabs)
- Standards and toolchain maturity. Existing NLP toolchains are token-centric. Adopting optical compression requires new tooling, benchmarks, and integration with retrieval/LLM stacks. Community uptake will depend on tooling maturity and standardized evaluation protocols. (GitHub)
Broader impacts on future AI systems
- Enabling truly long-context LLMs: If the technique proves robust and generalizable, we may see LLM systems that operate over orders-of-magnitude longer contexts at practical cost—changing the kinds of applications that are feasible (e.g., whole-book reasoning, nation-scale document analysis). (Tom’s Hardware)
- Hybrid modalities as standard design pattern. This work strengthens the case that representation modality selection (text vs. image vs. sparse embeddings) is a design choice for scaling and efficiency. Expect more hybrid encoders (text+visual+graph) optimized for cost vs. fidelity tradeoffs. (arxiv.org)
- New retrieval and indexing architectures. Search and memory systems may index “visual tokens” or compressed optical snapshots instead of, or in addition to, text embeddings—potentially improving layout-aware search (tables, spreadsheets, forms). (skywork.ai)
- Practical democratization of long-document AI. Lower operational cost for processing huge document collections makes advanced document AI accessible to smaller labs and companies, not only hyperscalers—accelerating applied research in domains like medicine, finance, law, and scientific literature mining. (The Times of India)
- Ethical, legal, and governance questions. Easier large-scale extraction from scanned material raises privacy and copyright concerns (bulk conversion of books, archived material). Responsible use, data provenance, and compliance workflows will be important. (skywork.ai)
Where the research could go next
- Better encoder/decoder co-design: More efficient architectures that shift less compute into the visual encoder while preserving fidelity. (arxiv.org)
- Hybrid lossy/lossless modes: Tools that let practitioners choose which passages require lossless recovery and which can be aggressively compressed. (iWeaver)
- Standard benchmarks: New benchmarks for “optical compression fidelity” across languages, scripts, table types, and diagrams. (skywork.ai)
- Hardware co-optimization: Custom compute kernels or accelerators for high-res image→token pipelines to improve throughput and energy efficiency. (Tom’s Hardware)
Short, practical takeaway
DeepSeek-OCR is not just “another OCR”; it’s an experimental representation and compression paradigm that maps long text+layout into visual form to reduce token costs for downstream reasoning. Early results and open releases indicate substantial promise (large token reductions, good fidelity at modest compression), but the approach introduces new tradeoffs (lossiness, different compute distribution, robustness questions). If the community validates and extends it, the technique could materially change how future LLM systems handle huge contexts and richly formatted documents. (arxiv.org)

Release
- [2025/10/23]🚀🚀🚀 DeepSeek-OCR is now officially supported in upstream vLLM. Thanks to the vLLM team for their help.
- [2025/10/20]🚀🚀🚀 We release DeepSeek-OCR, a model to investigate the role of vision encoders from an LLM-centric viewpoint.
Contents
Install
Our environment is cuda11.8+torch2.6.0.
- Clone this repository and navigate to the DeepSeek-OCR folder
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
- Conda
conda create -n deepseek-ocr python=3.12.9 -y conda activate deepseek-ocr
- Packages
- download the vllm-0.8.5 whl
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl pip install -r requirements.txt pip install flash-attn==2.7.3 --no-build-isolation
Note: if you want vLLM and transformers codes to run in the same environment, you don’t need to worry about this installation error like: vllm 0.8.5+cu118 requires transformers>=4.51.1
vLLM-Inference
- VLLM:
Note: change the INPUT_PATH/OUTPUT_PATH and other settings in the DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
- image: streaming output
python run_dpsk_ocr_image.py
- pdf: concurrency ~2500tokens/s(an A100-40G)
python run_dpsk_ocr_pdf.py
- batch eval for benchmarks
python run_dpsk_ocr_eval_batch.py
[2025/10/23] The version of upstream vLLM:
uv venv source .venv/bin/activate # Until v0.11.1 release, you need to install vLLM from nightly build uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Create model instance
llm = LLM(
model="deepseek-ai/DeepSeek-OCR",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor]
)
# Prepare batched input with your image file
image_1 = Image.open("path/to/your/image_1.png").convert("RGB")
image_2 = Image.open("path/to/your/image_2.png").convert("RGB")
prompt = "<image>\nFree OCR."
model_input = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_1}
},
{
"prompt": prompt,
"multi_modal_data": {"image": image_2}
}
]
sampling_param = SamplingParams(
temperature=0.0,
max_tokens=8192,
# ngram logit processor args
extra_args=dict(
ngram_size=30,
window_size=90,
whitelist_token_ids={128821, 128822}, # whitelist: <td>, </td>
),
skip_special_tokens=False,
)
# Generate output
model_outputs = llm.generate(model_input, sampling_param)
# Print output
for output in model_outputs:
print(output.outputs[0].text)
Transformers-Inference
- Transformers
from transformers import AutoModel, AutoTokenizer import torch import os os.environ["CUDA_VISIBLE_DEVICES"] = '0' model_name = 'deepseek-ai/DeepSeek-OCR' tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True) model = model.eval().cuda().to(torch.bfloat16) # prompt = "<image>\nFree OCR. " prompt = "<image>\n<|grounding|>Convert the document to markdown. " image_file = 'your_image.jpg' output_path = 'your/output/dir' res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
or you can
cd DeepSeek-OCR-master/DeepSeek-OCR-hf python run_dpsk_ocr.py
Support-Modes
The current open-source model supports the following modes:
- Native resolution:
- Tiny: 512×512 (64 vision tokens)✅
- Small: 640×640 (100 vision tokens)✅
- Base: 1024×1024 (256 vision tokens)✅
- Large: 1280×1280 (400 vision tokens)✅
- Dynamic resolution
- Gundam: n×640×640 + 1×1024×1024 ✅
Prompts examples
# document: <image>\n<|grounding|>Convert the document to markdown. # other image: <image>\n<|grounding|>OCR this image. # without layouts: <image>\nFree OCR. # figures in document: <image>\nParse the figure. # general: <image>\nDescribe this image in detail. # rec: <image>\nLocate <|ref|>xxxx<|/ref|> in the image. # '先天下之忧而忧'
Visualizations
