The stable version of Gemini 2.5 Flash-Lite is now generally available, marking a significant milestone in Google’s AI model family. This release represents our fastest and most cost-efficient model yet, priced at just $0.10 per 1M input tokens and $0.40 per 1M output tokens. Designed to push the boundaries of intelligence per dollar, Gemini 2.5 Flash-Lite comes with native reasoning capabilities that can be optionally activated for more demanding use cases.
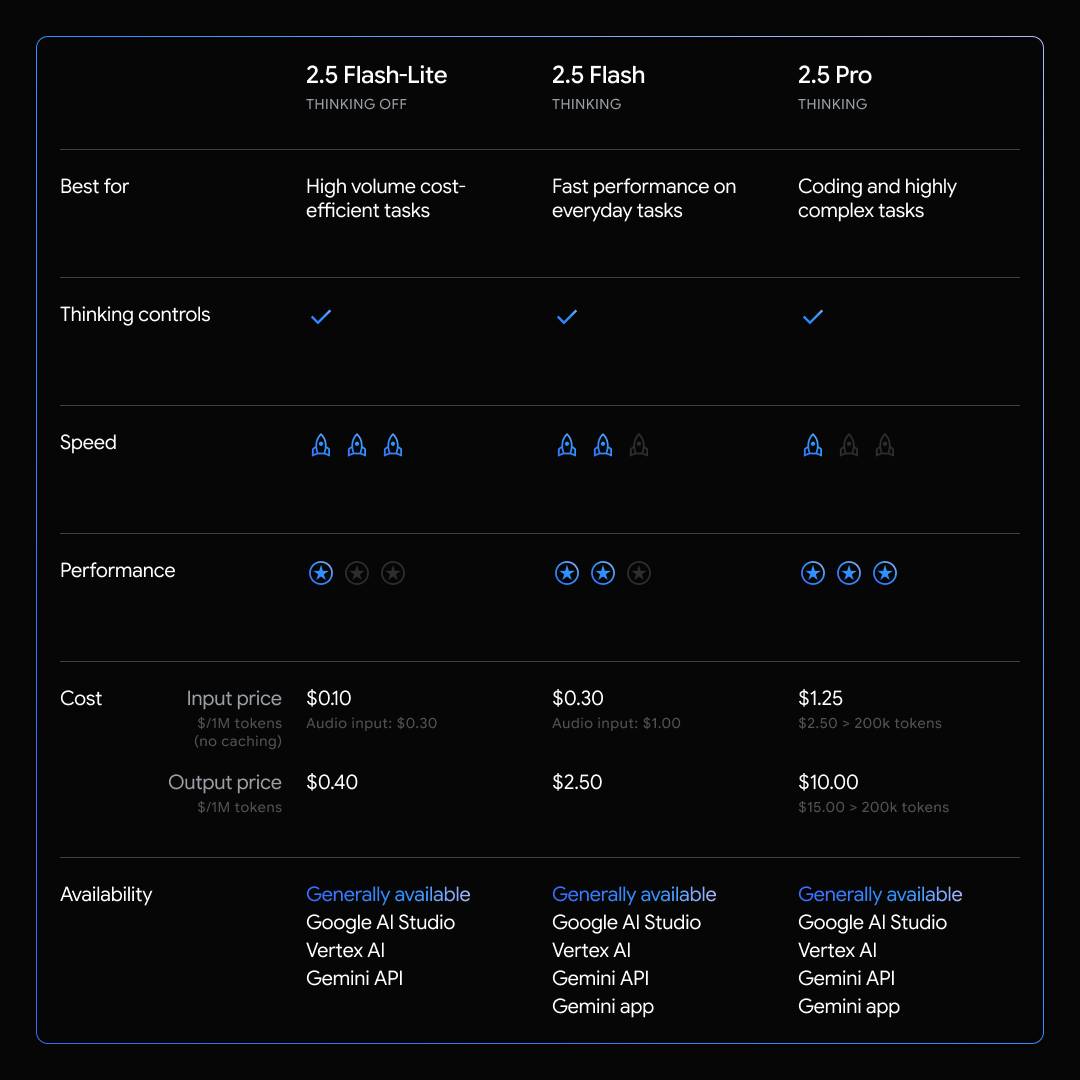
What makes Gemini 2.5 Flash-Lite truly stand out is its exceptional balance between performance and cost-effectiveness. The model delivers best-in-class speed with lower latency than both 2.0 Flash-Lite and 2.0 Flash across a broad range of prompts. Beyond its impressive speed, we’ve also reduced audio input pricing by 40% from the preview launch, making it even more accessible for various applications.
The model demonstrates superior quality across multiple benchmarks including coding, mathematics, scientific reasoning, and multimodal understanding. Developers gain access to a comprehensive feature set including a 1 million-token context window, controllable thinking budgets, and support for native tools like Grounding with Google Search, Code Execution, and URL Context.
Real-world implementations are already showcasing remarkable results. Satlyt has achieved a 45% reduction in latency for critical onboard diagnostics and a 30% decrease in power consumption for their decentralized space computing platform. HeyGen leverages the model to automate video planning and translate content into over 180 languages, while DocsHound processes long videos to extract thousands of screenshots with minimal latency. Evertune uses the model to dramatically accelerate analysis and report generation, providing clients with dynamic, timely insights.

Developers can immediately start building with the stable version by specifying “gemini-2.5-flash-lite” in their code. For those using the preview version, switching to the stable release is seamless as it’s the same underlying model. The preview alias will be retired on August 25th, so now is the perfect time to transition.

Ready to explore what Gemini 2.5 Flash-Lite can do for your projects? The model is available now in both Google AI Studio and Vertex AI, providing developers with powerful tools to create innovative applications while maintaining cost efficiency and exceptional performance.

This release completes the Gemini 2.5 model family, joining 2.5 Pro and 2.5 Flash to offer a comprehensive suite of models ready for scaled production use. Whether you’re working on translation tasks, classification systems, or complex multimodal applications, Gemini 2.5 Flash-Lite delivers the speed, intelligence, and affordability needed for today’s demanding AI workloads.